The Jenkins Trap: Why Monolithic Pipelines Fail in the Cloud
Still building CI/CD pipelines with Jenkins? Discover why monolithic servers and complex scripting fail in modern cloud engineering.
If you are transitioning into DevOps from system administration or network engineering, you are hardwired to manage servers. When you are tasked with building a CI/CD pipeline, your instinct is to look for a server to install, configure, and maintain.
This instinct leads almost everyone straight to Jenkins.
Jenkins is comfortable. It gives you a dashboard, a recognizable master server, and a place to install updates.
And, you can easily end up building a CICD pipeline that looks like this.
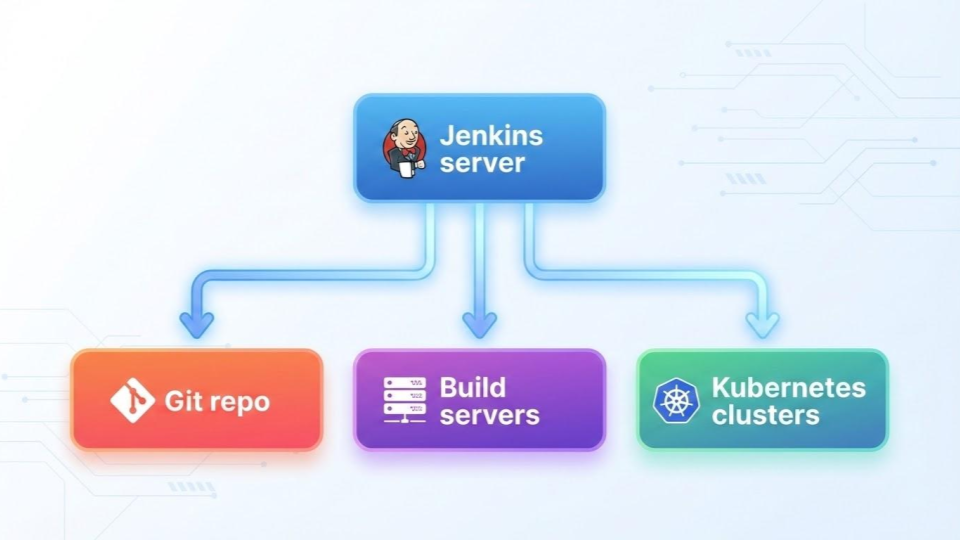
This exactly is the "CI/CD box" we debunked in Part 1 of this series. In modern cloud engineering, treating your pipeline as a centralized monolithic appliance is a massive trap.
While Jenkins paved the way for automation a decade ago, building an end-to-end pipeline with it today often directly contradicts the principles of cloud-native design. Here is why the Jenkins monolith fails in the cloud, and why you should avoid it.
1. The Return of the "Pet" Server
In modern DevOps, infrastructure should be treated like "cattle"—ephemeral, disposable, and easily recreated from code.
Jenkins, however, almost always becomes a "pet." The Jenkins Master server is a fragile monolith. You have to patch the underlying Linux OS, update the Java runtime, manage its disk space, and back up its XML configuration files. If your Jenkins server goes down, your entire organization’s ability to ship software stops dead. You end up spending more time keeping the CI/CD server alive than you do deploying actual application code.
2. Plugin Purgatory
Out of the box, Jenkins does very little. To make it useful—whether you are compiling a Go microservice, running tests for a Ruby on Rails engine, or executing an Ansible playbook—you have to install third-party plugins.
This leads to "Plugin Purgatory." Because these plugins are largely community-maintained, they frequently break, conflict, or become abandoned. You often find yourself in a scenario where updating the Jenkins core breaks your AWS deployment plugin, and rolling back the AWS plugin breaks your Git integration. The pipeline becomes a fragile Frankenstein's monster.
3. Imperative Scripting vs. Declarative State
Cloud-native engineering relies heavily on declarative code. You declare the end state you want (usually in a clean, readable YAML file), and the system figures out how to get there.
Jenkins pipelines, on the other hand, are traditionally built using Groovy, an imperative scripting language. Instead of simply declaring what you want to happen, you have to write complex, step-by-step programming logic just to move an artifact from point A to point B. This drastically steepens the learning curve and results in pipeline code that is incredibly difficult for other engineers to read and maintain.
4. A Massive Security Blast Radius
When a single centralized tool is responsible for downloading source code, building container images, and deploying to production, that tool needs the keys to everything.
A monolithic Jenkins server usually holds the credentials for your Git repository, your artifact registries, your AWS environments, and your Kubernetes clusters. If an attacker exploits a vulnerability in just one outdated Jenkins plugin, they instantly gain root-level access to your entire infrastructure stack. In contrast, a distributed pipeline isolates these permissions, drastically shrinking the blast radius.
5. Cloud-Native is Bolted On, Not Built In
Jenkins was designed in an era of bare-metal servers and virtual machines. While you certainly can force it to work with modern paradigms like ephemeral containers and Kubernetes, it always feels bolted on.
Modern CI/CD platforms—like GitHub Actions or GitLab CI—were built from the ground up assuming that every single build step would run inside an isolated, disposable container. They natively understand cloud-native workflows, making them vastly more efficient and secure out of the box.
Escaping the Trap
Jenkins deserves enormous respect for teaching the industry how to automate. But as a fresh DevOps engineer, you need to build for the future, not the past.
Break the monolithic mindset. Stop building pet servers. Instead, embrace distributed, event-driven CI/CD tools that use declarative YAML, leverage ephemeral build runners, and integrate natively with the cloud.
Your future self (and your pager) will thank you.

Indika Kodagoda
Indika Kodagoda is a Lead DevOps Engineer, AWS certification instructor, and the creator of CloudQubes. He specializes in cloud infrastructure, automation, and modern Ruby on Rails development. When he’s not deploying code or mentoring aspiring engineers, he’s usually enjoying nature and cycling local gravel paths.