Kafka for DevOps: Supercharging Your Cloud-Native Architectures
Unlock the power of Apache Kafka for DevOps. Learn how to decouple microservices, centralize real-time log aggregation, and build resilient, scalable cloud-native architectures with this comprehensive introductory guide.
Traditional monolithic architectures are giving way to dynamic, distributed systems, often built on microservices and cloud-native principles.
But this shift brings new challenges: managing complex inter-service communication, processing vast streams of operational data, and maintaining system observability.
This is the problem that Apache Kafka can help you with.
More than just a simple message queue, Kafka is a distributed streaming platform designed to handle high-throughput, fault-tolerant, and real-time data feeds. For DevOps engineers, it's not just another tool; it's a foundational component that can supercharge your cloud-native architectures, decouple your services, and provide invaluable insights into your operational landscape.
In this post, we'll dive into what makes Kafka a must-have for modern DevOps toolkits, explore its core concepts, and highlight practical use cases that solve real-world problems.
What is Apache Kafka? (The 5-Minute Primer)
Imagine a meticulously organized, high-speed postal service designed specifically for data. This isn't just about sending letters; it's about continuously streaming every event, log, metric, and transaction that happens across your entire ecosystem. That's essentially Apache Kafka.
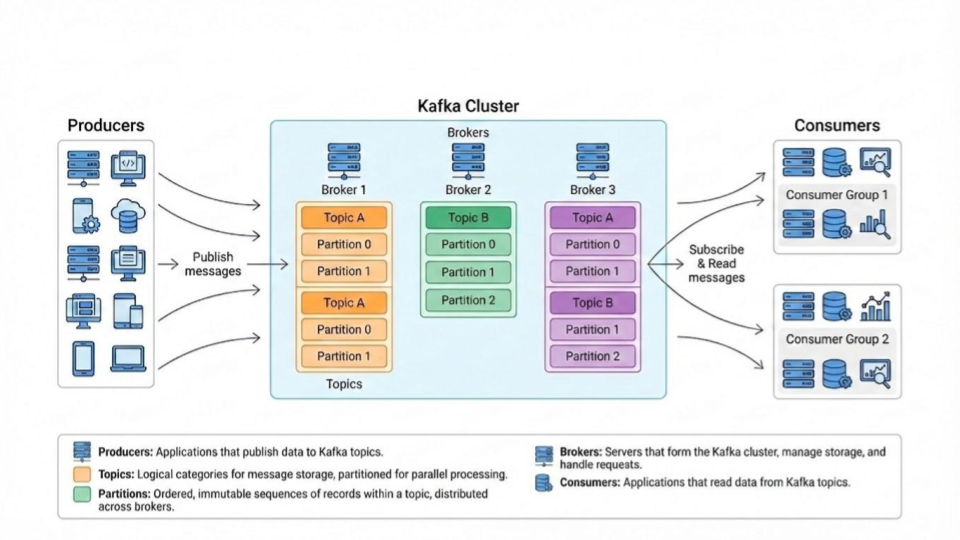
At its core, Kafka is a distributed commit log. It allows applications (called Producers) to publish streams of records to various categories (called Topics). Other applications (called Consumers) can then subscribe to these topics and process the records in real-time.
Here’s a quick breakdown of its fundamental components:
- Producers: Your applications, microservices, or data sources that generate events and write them to Kafka topics.
- Consumers: Applications that read events from Kafka topics to process, analyze, or store them.
- Topics: Named feeds of records. Think of them as categories for your data streams (e.g.,
user_logins,order_updates,system_metrics). - Partitions: Each topic is divided into one or more partitions. This is how Kafka achieves massive scalability and allows for parallel consumption. Records within a partition are strictly ordered.
- Brokers: These are the Kafka servers. A collection of brokers forms a Kafka Cluster, distributing partitions and replicating data for fault tolerance.
Kafka's design emphasizes durability, high throughput, and horizontal scalability, making it ideal for handling the immense data volumes of modern distributed systems.
Here's a visual to help understand the core data flow:
Why DevOps Engineers Should Care: Solving Real-World Problems
For DevOps engineers, Kafka isn't just an abstract data platform; it's a powerful tool that directly addresses several critical pain points in managing, scaling, and observing complex cloud-native environments.
Problem 1: Decoupling Services in Microservices Architectures
- The Challenge: In a microservices architecture, direct API calls between services create tight coupling. If one service goes down, it can cause cascading failures across dependent services. Deployments become riskier, and scaling individual services independently is harder.
- Kafka's Solution: Asynchronous, Event-Driven Communication. Kafka acts as an intermediary, allowing services to communicate asynchronously. Producers publish events without needing to know which consumers will read them, or even if any consumers are currently active. Consumers read events at their own pace. This creates a highly decoupled system that is more resilient to individual service failures and allows for independent scaling and deployment of microservices.
Problem 2: Real-time Data Ingestion & Processing (Logs, Metrics, Events)
- The Challenge: Collecting, aggregating, and analyzing operational data (logs, metrics, audit trails, user activity) from hundreds or thousands of ephemeral containers and services is a monumental task. Traditional batch processing leads to delayed insights, making quick incident response or real-time analytics impossible.
- Kafka's Solution: A Centralized, High-Throughput Pipeline. Kafka excels at handling massive streams of data from diverse sources. It can act as the central nervous system for all your operational telemetry. Logs from Fluentd, metrics from Prometheus exporters, application events – all can flow into Kafka. This enables immediate processing by various consumers for real-time dashboards, anomaly detection, and automated alerts, transforming reactive operations into proactive management.
Problem 3: Achieving Scalability & Resilience
- The Challenge: Ensuring your messaging infrastructure can scale with your application's growth and remain available even when components fail is crucial. Traditional message queues often struggle with horizontal scalability or have single points of failure.
- Kafka's Solution: Inherently Distributed and Fault-Tolerant. Kafka is designed from the ground up to be distributed. Topics are partitioned across multiple brokers, allowing you to scale throughput by simply adding more brokers to your cluster. Data is replicated across multiple brokers (configured per topic) ensuring that even if a broker fails, your data remains accessible and production can continue without interruption. This provides high availability and robust data durability.
Problem 4: Event Sourcing & Data Replay
- The Challenge: Debugging intermittent issues, auditing system behavior, or recreating application state often requires a complete historical record, which is rarely readily available in traditional setups.
- Kafka's Solution: A Durable, Immutable Log. Unlike many message queues that delete messages once they're consumed, Kafka persists all records to disk for a configurable period (days, weeks, or even indefinitely). This makes it an ideal platform for event sourcing, where every state change in your application is recorded as an event. You can "replay" these events to reconstruct application state, debug complex issues, perform historical analysis, or even test new features against past production data.
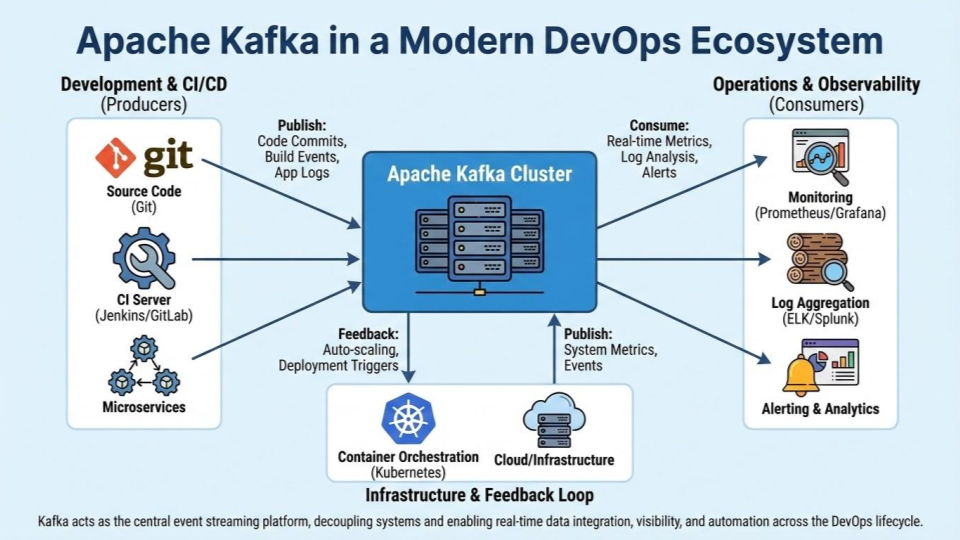
Key DevOps Use Cases for Kafka
Leveraging Kafka can profoundly impact your operational workflows. Here are some prime examples:
- Centralized Log Aggregation: Ship logs from all your services (containers, VMs, serverless functions) into Kafka. From there, dedicated consumers can forward them to your SIEM (e.g., Splunk), log management system (e.g., ELK Stack, Grafana Loki), or data lake for analysis and archival. Kafka provides a robust, scalable buffer against log ingestion spikes.
- Metrics Collection and Monitoring: Integrate Kafka into your metrics pipeline. Instead of pushing metrics directly to a time-series database, send them through Kafka. This decouples metric producers from consumers, allowing multiple monitoring systems to consume the same data, facilitating real-time anomaly detection and operational dashboards.
- Change Data Capture (CDC): Implement CDC solutions (like Debezium) to capture row-level changes from your databases and stream them into Kafka. This enables real-time synchronization between microservices, populating search indexes, or feeding a data warehouse without impacting primary database performance.
- Inter-Service Communication for Microservices: As discussed, Kafka becomes the backbone for asynchronous communication between your microservices, enabling true event-driven architectures where services react to events rather than tightly coupled requests.
- Command and Event Queue for Automation: Use Kafka to queue commands for automation scripts or to trigger CI/CD pipelines based on specific events (e.g., a new commit, a successful build, or a resource scaling event).
Here's an illustration of Kafka's role in a modern DevOps ecosystem:
Deploying Apache Kafka: A DevOps Perspective
Transitioning from understanding Kafka to implementing it requires a shift in how you think about infrastructure management. For a DevOps engineer, the focus should be on operational sustainability, observability, and security.
Deployment Strategies
- Managed Services: If you want to focus on application logic rather than cluster maintenance, managed services like AWS MSK or Google Cloud Managed Service for Apache Kafka are the gold standard. They handle the "heavy lifting" of patching, scaling, etc.
- Self-Managed: For teams that prefer full control, deploying Kafka on Kubernetes is the most common path. Using operators like Strimzi makes managing Kafka clusters "Kube-native," handling complex tasks like rolling updates and topic management through Custom Resources (CRDs).
Essential Observability
Keep your eyes on these three pillars to make sure your Kafka cluster's performance is optimal:
- Consumer Lag: The most critical metric. It tells you how far behind your consumers are from the latest data. High lag usually means your processing logic is too slow or you need more consumer instances.
- Disk Utilization: Since Kafka persists data to disk, running out of space is a cluster-killer. Monitor your retention policies closely.
- Broker Health: Watch your Under-Replicated Partitions (URPs). If this number is greater than zero, your data isn't being properly backed up across brokers.
Security First
Kafka is the "central nervous system," so securing it is non-negotiable. Always implement TLS encryption for data in transit and SASL/Scram or mTLS for authentication. Use ACLs (Access Control Lists) to ensure that Service A can only write to its own topic and cannot "peek" into Service B's data.
Conclusion
In the modern cloud-native landscape, the ability to process data in motion is no longer a luxury—it’s a requirement. Apache Kafka has evolved from a simple LinkedIn tool into the backbone of the world's most resilient distributed systems.
For DevOps engineers, Kafka is the key to breaking down monoliths, gaining real-time visibility into system health, and building architectures that don't just survive failures but gracefully handle them. Whether you are aggregating logs from a thousand microservices or building a real-time fraud detection engine, Kafka provides the throughput, durability, and scalability to make it happen.
The learning curve can be steep, but the payoff is a decoupled, observable, and highly elastic infrastructure. Ready to supercharge your architecture? Start small, pick a single use case—like centralized logging—and watch how Kafka transforms your data flow.

Indika Kodagoda
Indika Kodagoda is a Lead DevOps Engineer, AWS certification instructor, and the creator of CloudQubes. He specializes in cloud infrastructure, automation, and modern Ruby on Rails development. When he’s not deploying code or mentoring aspiring engineers, he’s usually enjoying nature and cycling local gravel paths.