Beyond the IDE: Deploying Agentic AI into Production
Ready to take AI agents into production? Explore the 2026 landscape of Agentic AI orchestration, SDKs, and the dilemma of cloud vs. local model execution.
Working with Cursor, Windsurf, or Google Antigravity.
You know it.
You ask the AI agent to fix a bug. Instead of just spitting out a code snippet, it actually rolls up its sleeves, digs through three different files, runs your test suite, encounters an error, and fixes its own mistake before presenting you with a perfect pull request.
It feels like magic. But as impressive as these AI-first IDEs are, they represent just the tip of the iceberg.
Right now, we are witnessing a massive shift in how organizations think about AI. Developers are looking at these highly capable coding agents and asking the obvious next question: "If this AI can autonomously navigate my codebase and fix bugs on my laptop, why can’t I take that same reasoning engine and plug it directly into my actual backend application?"
That question marks the boundary of the next major tech frontier: taking agents beyond the IDE.
Moving an agent off your local desktop and deploying it as a production-grade enterprise service is a completely different ballgame. It means moving away from a tool that sits quietly inside your code editor to building a sovereign, managed cloud service. Imagine autonomous agents running 24/7 in your cluster—monitoring database health, automatically patching vulnerabilities, processing complex multi-step user workflows, or dynamically managing cloud infrastructure costs.
But how do you actually build something like that? How do these systems work under the hood when they aren't tied to a visual code editor? And what tools are available right now to help you build them?
In this article, we’re going to look past the developer desktop. We will deconstruct the decoupled architecture of production agents, map out the current SDK landscape (both open-source and commercial), and weigh the massive architectural dilemma every cloud architect is currently facing: should you run your agent's brain in the cloud, or keep it fully local and air-gapped?
Let's dive in.
Deconstructing the Agent Architecture: Orchestration Layer vs. Backend
To successfully take an agent out of the IDE, we first have to demystify what an agent actually is. When you are using an AI-first editor, it feels like a single, cohesive piece of software. But under the hood, a production-grade agent is actually split into two completely separate pieces: the Orchestration Layer and the Intelligence Layer.
Think of it like a corporate structure. You have the Manager (the Orchestration Layer) who sits at the desk, manages the files, tracks the project timeline, and talks to clients. Then you have the Specialist Consultant (the Intelligence Layer) whom the manager calls on the phone whenever they need a complex problem analyzed.
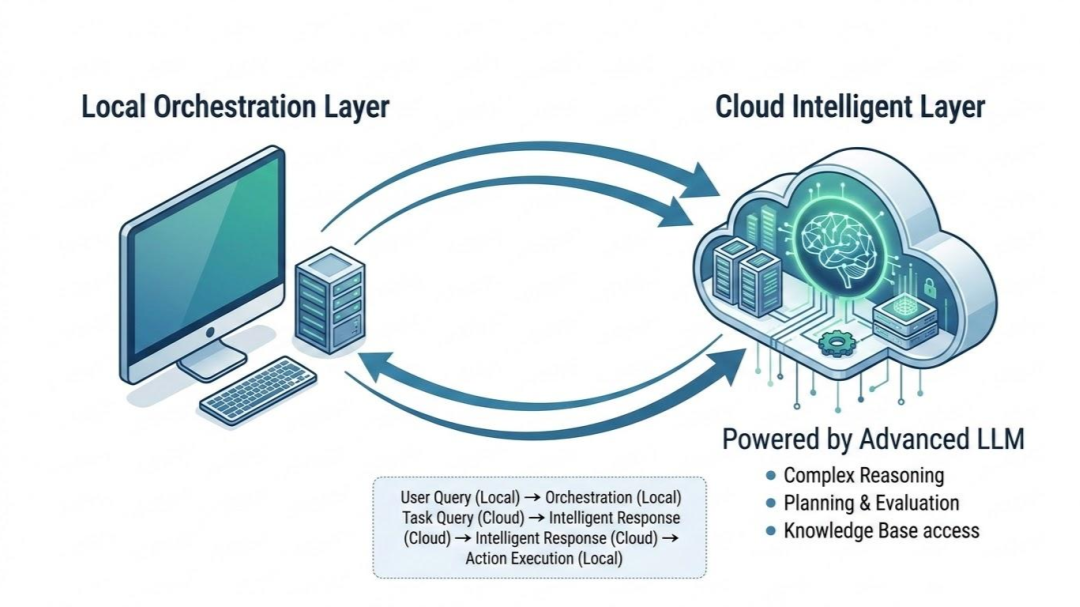
Understanding this decoupling is the secret to building your own enterprise AI services. Let’s break down exactly what each layer does.
1. The Orchestration Layer (The State Machine)
The orchestration layer is the actual application code you write and deploy on your cloud infrastructure (like a Docker container running in AWS, Google Cloud, or Azure). It acts as the backbone of the entire operation.
This layer is deterministic, meaning it follows strict rules and logic that you control. It is responsible for:
- The Execution Loop: Managing the continuous cycle of "Plan, Act, Observe, and Adjust."
- State & Memory Management: Keeping track of what the agent has already done, what it is currently doing, and what its long-term goals are. It stores the active "scratchpad" memory.
- Tool Execution: This is the only layer that can actually touch your infrastructure. If the agent needs to query a SQL database, call a Stripe API, or read a file, the orchestration layer physically executes that local code.
2. The Intelligence Layer (The LLM Backend)
The intelligence layer is the raw Large Language Model itself (like Gemini 3.1 Pro or Claude 4.5). It is completely stateless—it has no memory of past conversations, no awareness of time, and no native ability to run code or access the internet. It is purely a text-in, text-out reasoning engine.
Whenever the Orchestration Layer gets stuck or needs to make a decision, it packages up the current state of the world into a text prompt and hands it to the Intelligence Layer. It asks: "Given this goal, and given that the last database query returned an error, what should our very next step be?"
The LLM processes the text and sends back an instruction—usually in a structured format like JSON—saying something like: "You should execute the repair_table_schema tool with these specific parameters."
How They Dance Together
To see how this works in a real production environment outside of an IDE, let’s look at a quick lifecycle of an autonomous customer support agent handling a complex refund request:
- The Trigger: A customer requests a refund via an API webhook.
- The Orchestration Layer catches the webhook, initializes a new session state, and sends the request to the Intelligence Layer asking for a plan.
- The Intelligence Layer reasons through the request and replies: "We need to check their purchase history first. Call the
get_user_historytool." - The Orchestration Layer reads that instruction, physically queries your internal database, gets the data, and sends it back to the LLM: "Here is the data. What next?"
- The Intelligence Layer analyzes the history, notices the customer is a VIP, and says: "Approve the refund. Call the
trigger_stripe_refundtool." - The Orchestration Layer executes the payment gateway call, updates your database, logs the completion, and closes the loop.
Why this matters: Because these two layers are decoupled, you aren't locked into a single AI provider. If a faster, cheaper LLM comes out tomorrow, you can completely swap out your Intelligence Layer backend without changing a single line of your core tool execution or business logic in the Orchestration Layer.
Mapping the Production Tool Landscape
If you want to build an autonomous backend service today, you don't have to start from scratch. The market has exploded with SDKs and frameworks designed to help you wire up these orchestration and intelligence layers.
However, because the space is moving so fast, the tooling landscape is incredibly noisy. To make sense of it, let’s break the market down into three distinct categories: The AI Giants (The Intelligence APIs), Commercial Orchestration SDKs, and Open-Source Frameworks.
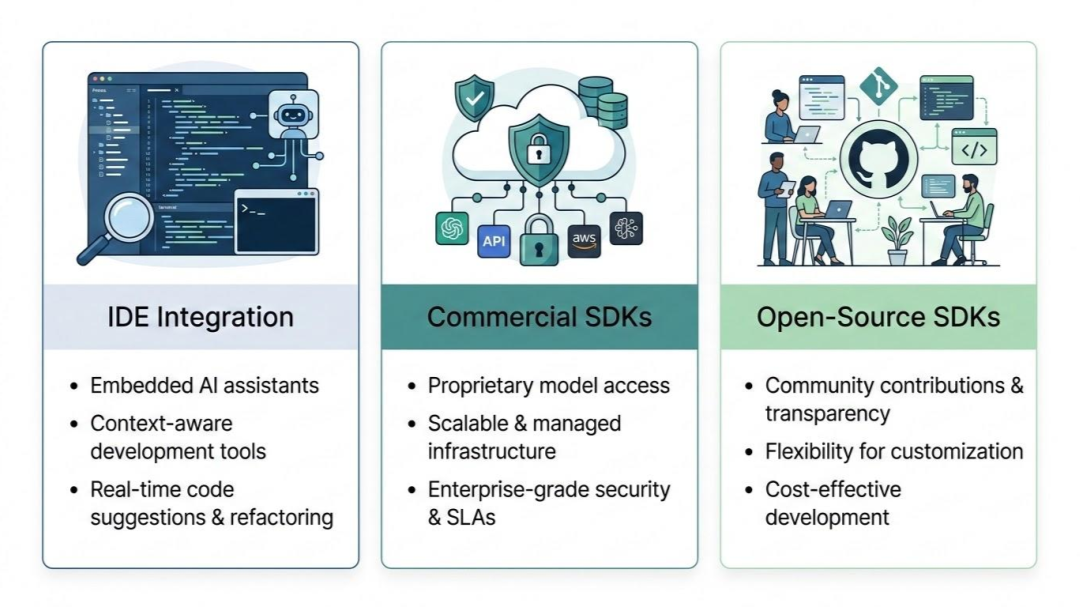
1. The AI Giants (Intelligence APIs & Native Tooling)
When building a production agent, the models you choose for your backend matter. Both OpenAI and Anthropic are doing more than just providing raw LLMs; they are building developer ecosystems to make tool orchestration easier.
- Anthropic (Claude & MCP): Claude has become the gold standard for reliable tool execution. But Anthropic’s biggest contribution to the agent landscape isn't just their model—it’s the Model Context Protocol (MCP). Think of MCP like USB-C for AI agents. Instead of writing custom API wrappers for every tool, MCP allows Claude (and other supported agents) to plug directly into enterprise databases, Slack, or GitHub using a universal standard.
- OpenAI (Assistants API & Swarm): OpenAI makes building simple agents incredibly accessible via their Assistants API, which handles memory (thread state) and tool-calling natively on their servers. For developers looking to experiment with multi-agent setups, OpenAI recently open-sourced Swarm—a lightweight, highly controllable framework that lets developers pass complex tasks back and forth between different OpenAI models (like passing a task from an o1-preview "thinker" to a GPT-4o "coder").
2. Commercial Orchestration SDKs
If you are operating inside a specific cloud ecosystem, the major providers are rolling out powerful enterprise-grade orchestration tools.
- Google Antigravity SDK: If you love the Antigravity agent in your IDE, Google’s new SDK lets you extract that exact same runtime and embed it in your Python backend. It features native MCP support and built-in safety hooks (
Inspect,Decide), allowing you to pause the agent for human approval before it executes a high-risk cloud command. - Gemini Enterprise Agent Platform (formerly Vertex AI): This is Google's heavy-duty hosting environment. Once you write your agent script, this platform runs it securely, grounding the agent in your company’s proprietary data while enforcing strict enterprise compliance and rate limits.
3. Open-Source Orchestration Frameworks (The Developer Favorites)
If you want total control over your orchestration layer without being locked into a specific vendor's ecosystem, the open-source community is where the most exciting innovation is happening.
- LangGraph: This is currently the industry heavyweight for production workflows. LangGraph forces you to define your agent’s "Plan-Act-Observe" loop as a cyclical graph (a state machine). This makes it highly deterministic—meaning you can perfectly predict how the agent will route information, making it the safest choice for enterprise pipelines.
- CrewAI / AutoGen: If LangGraph is for rigid pipelines, these frameworks are for collaboration. They allow you to define a "crew" of specialized micro-agents. You can spin up a "Data Engineer Agent" and a "QA Agent," give them a shared memory bus, and let them talk to each other to solve a problem before returning the final result to your users.
The takeaway: You don’t have to pick just one. A modern, robust architecture might use LangGraph to manage the execution loop locally, use MCP to connect to internal tools, and ping Anthropic’s Claude in the cloud to act as the primary intelligence engine.
The Architectural Dilemma: Cloud vs. Local Execution
If you are building an agentic service, you are eventually going to hit the biggest architectural roadblock of 2026: Where exactly does the "brain" live?
Because the Orchestration Layer and the Intelligence Layer are decoupled, you have a massive choice to make regarding your LLM backend. Do you lease intelligence from a cloud provider, or do you buy the hardware and run the models yourself?
This isn't just a slight difference in deployment strategy; it completely changes your security posture, your latency, and your monthly cloud bill. Let’s look at the two paths.
Path A: The Cloud API Backend (The Default Choice)
This is where most teams start. Your orchestration code runs on your servers, but every time the agent needs to "think," it fires an API request over the internet to a frontier model like Gemini 3.1 Pro or Claude 4.5.
- The Pros: You get the absolute smartest reasoning engines on the planet with zero hardware maintenance. If your agent is handling incredibly complex tasks—like reverse-engineering legacy code or planning multi-step system migrations—you want a cloud frontier model.
- The Cons: You pay per token. When an agent gets stuck in a loop and makes 30 rapid-fire API calls to debug a single issue, your costs scale linearly. Furthermore, your data—including proprietary system logs or customer information—leaves your Virtual Private Cloud (VPC) to hit external endpoints, which can be a non-starter for compliance-heavy industries.
Path B: The Local, Air-Gapped Backend (The Sovereign Agent)
The alternative is downloading an open-weight model (like Llama 4 or Gemma) and running it entirely on your own infrastructure using a serving engine like vLLM or Ollama.
- The Pros: Total data sovereignty. Your code and logs never leave your network, making it the only viable choice for strict enterprise security. Additionally, your marginal cost per token drops to zero. Once you own the hardware, the agent can loop and think a million times a day without racking up a massive API bill.
- The Cons: Running a production-grade 70-billion-parameter model locally is heavy. While it's easy to test an agent's orchestration logic using Ollama on a MacBook Pro, moving that to production requires serious, expensive GPU instances. Your agent is also limited to the reasoning capabilities of the open-source model you choose, which may struggle with edge cases that a frontier cloud model would solve effortlessly.
The Break-Even Point
Right now, the industry is settling on a hybrid approach based on volume and data sensitivity.
If your agent makes a few hundred decisions a day, the cloud API is vastly cheaper than keeping a heavy GPU instance idling 24/7. However, if you are running automated pipelines that process millions of tokens daily, the math flips. Many organizations are finding that at high volumes, a dedicated, air-gapped agent pays for its own infrastructure within the first six to twelve months.
The Architect's Playbook: Use cloud APIs for the "Planner" agents that require deep reasoning, but deploy local, smaller models for the "Implementer" sub-agents that just need to execute high-volume, repetitive tasks like text extraction or log formatting.
Challenges: The Reality Check of Autonomy
As exciting as it is to think about a fleet of digital workers handling your operations 24/7, deploying autonomous agents into production isn't all sunshine and rainbows. Moving from a traditional, predictable codebase to a probabilistic agentic system introduces some completely new engineering and operational challenges that your team needs to be ready for.
1. The Infinite Loop (And the Exploding API Bill)
In traditional software, if a script hits a wall, it throws an error and crashes. It stops. When an autonomous agent encounters an error, its entire purpose is to figure out a workaround. It will read the error, rewrite a piece of code, try again, encounter a new error, write another patch, and keep going.
If you don't build strict limits into your orchestration layer, agents can easily fall into "hallucination loops"—spending hours trying to solve an impossible or poorly phrased problem. Because every single attempt requires calling an LLM under the hood, an unmonitored agent running wild can rack up thousands of dollars in cloud API costs in a single afternoon. Building in maximum execution caps and hard cost-per-task budgets is an absolute necessity.
2. The Loss of Determinism
Enterprise software loves predictability. If a user clicks a button or an automation runs at midnight, you want the exact same thing to happen every single time.
Agents, by their very nature, are non-deterministic. If you give an agent the exact same goal three times, it might use three completely different tools or execution paths to get there. This makes testing, QA, and debugging a fascinating new challenge. If an agent introduces a subtle bug into an environment, your developers can’t just look at a static log file; they have to audit the agent’s entire cognitive chain-of-thought history to figure out why it made that specific decision.
3. The Trust Threshold & The Blast Radius
When an agent is running inside a developer's IDE, its "blast radius" is limited to that developer's laptop. If it deletes a file by accident, it’s annoying, but fixable.
When you take an agent into the cloud backend, its blast radius expands exponentially. If you give a production agent broad IAM permissions to "optimize your database performance," you need to be 100% sure it won't decide to drop a massive table to "clear up disk space."
This is why Human-in-the-Loop (HITL) guardrails are so vital. For low-risk tasks (like spinning up a local sandbox or formatting data), let the agent run completely free. But for high-risk infrastructure actions, your orchestration layer must be coded to pause, send a webhook (perhaps to a Slack channel or internal dashboard), and wait for a human to review the action and click "Approve."
The Way Forward
Taking agents beyond the IDE isn't about replacing human cloud engineers or software developers. It’s about elevating them.
We are moving away from an era where engineers spend the majority of their time on digital plumbing—writing repetitive boilerplate code, configuring brittle pipelines, and manually digging through logs. In the agentic era, your role shifts from being the builder to being the Orchestrator. Your job will be to design the state machines, set the guardrails, define the inputs, and manage teams of autonomous digital workers.
If you want to start preparing your infrastructure and your team for this shift today, here is the playbook:
- Audit your internal documentation: AI agents are only as good as the context you feed them. Clean up your internal API specs, markdown files, and schemas so an agent can actually understand them.
- Start small and sandboxed: Don't let an agent touch production on day one. Build a simple internal tool using an open-source framework like LangGraph or a commercial SDK, and let it automate safe, low-risk developer workflows first.
- Focus on identity and security: Treat agents like new employees. Give them their own highly restricted service accounts, monitor their API access, and design your approval gates early.
The autonomous cloud is no longer a futuristic concept—the primitives, the SDKs, and the models are live right now. The organizations that figure out how to safely scale these digital workers beyond the desktop are the ones that will define the next decade of cloud engineering.

Indika Kodagoda
Indika Kodagoda is a Lead DevOps Engineer, AWS certification instructor, and the creator of CloudQubes. He specializes in cloud infrastructure, automation, and modern Ruby on Rails development. When he’s not deploying code or mentoring aspiring engineers, he’s usually enjoying nature and cycling local gravel paths.